
CCDA API Implementation
Summary
C-CDA Files are at the core of what Particle does and are ultimately how EMRs share their data through the networks and HIEs Particle connects to. C-CDA files are traditionally in XML format and contain all information related to a patient's medical history relative to the specific institution we're pulling from. More detailed information on the HL7 CDA standards can be found here. After Particle has ingested C-CDA files, we convert them to other formats like FHIR R4 and our Flat JSON format, which are made available for our customers to utilize.
While a vast majority of the file types Particle receives are in XML format, other file types come through the networks, including PDFs, TIFF, PNGs, and JPEGs.
Note that Particle currently does not convert any non-XML file into downstream FHIR and Flat formats
If you're interested in downloading non-XML files (e.g. PDFs), Particle makes those available via the workflows described below, regardless of data format you initially request.
Image files returned should not be expected to have Radiology/Cardiology imaging
Particle does not typically have access to radiology imaging through the HIEs we're connected to. We will not, for example, receive full DICOM MRI or CT imaging, but we do commonly receive Radiology Impressions in the form of procedure summaries and free-text.
Your Particle team is happy to work with you to implement the best solution for your needs.
Query Workflow
In many cases, our clients will follow our Recommended Query Workflow, regardless of data format interest. If your contract provides access to all data types, we recommend starting here.
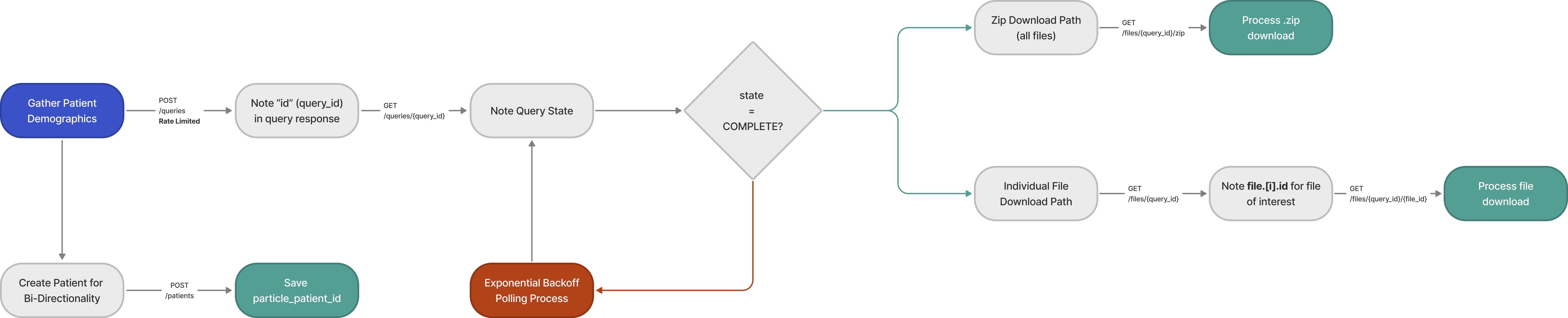
For customers that only need access to C-CDA files, the process follows the following workflow:
Polling for Query Status
Webhook for Query Status

Note that the same Webhook Notification functionality described in our Recommended Query Flow can be applied to C-CDA only queries. Your Particle team can work with you to configure these.
Document Metadata
All files retrieved from the network have an associated object of metadata. This metadata can be retrieved by calling the GET Queries endpoint.
An example of what Document Metadata can look like can be seen here:
{
"authenticator": "Jane Doe MD",
"author_name": "John Doe",
"author_organization": "Particle Health",
"class_code": "72170-4",
"confidentiality_code": "N",
"creation_time": "2020-01-01T00:00:00Z",
"event_code": "AMB",
"file_size": 2454,
"format_code": "urn:ihe:iti:xds:2017:mimeTypeSufficient",
"healthcare_facility_type_code": "35971002",
"id": "ac53cf7c-77ff-434f-8aa3-5966bc5c10ae",
"language_code": "en-US",
"practice_setting_code": "132",
"service_start_time": "2020-01-01T00:00:00Z",
"service_stop_time": "2020-01-01T00:00:00Z",
"status_code": "current",
"title": "Medical Summary",
"type": "application/xml",
"type_code": "34133-9",
"url": "/api/v1/files/4bcd32df-a013-432f-a56a-c8a8705f6653/ac53cf7c-77ff-434f-8aa3-5966bc5c10ae"
}
Below is a full breakdown of available metadata fields (note that these will all be Nullable, meaning if it is not available from the source, Particle will not respond with the field).
| Document Metadata Fields |
|---|
| Authenticator |
| Author Name |
| Author Organization |
| Class Code |
| Confidentiality Code |
| Creation Time |
| Document Type |
| Event Code |
| File Size |
| Format Code |
| Healthcare Facility Type Code |
| Language Code |
| Practice Setting Code |
| Service Start Time |
| Service End Time |
| Status Code |
| Title |
Downloading Individual Files
By calling the GET Queries (queries/{id}) endpoint, Particle customers can select which individual files, by ID, that they would like to download.
A sample response to this endpoint can be seen here:
{
"demographics": {
"address_city": "Brooklyn",
"address_lines": [
"999 Dev Drive"
],
"address_state": "New York",
"date_of_birth": "1954-12-01",
"email": "[email protected]",
"family_name": "Quark",
"gender": "MALE",
"given_name": "Kam",
"hints": [
"11111"
],
"npi": "9876543210",
"patient_id": "string",
"postal_code": "11111",
"purpose_of_use": "TREATMENT",
"specialties": [
"ONCOLOGY"
],
"ssn": "123-45-6789",
"telephone": "234-567-8910"
},
"files": [
{
"id": "ac53cf7c-77ff-434f-8aa3-5966bc5c10ae",
"type": "application/xml",
"..."
},
{
"id": "a082a279-4060-4c05-9d18-467f561b0ab1"
"type": "application/xml",
"..."
},
{
"id": "ab533954-5b2c-43a0-82d2-4b21d06d7837",
"type": "application/pdf",
"..."
}
],
"id": "4bcd32df-a013-432f-a56a-c8a8705f6653",
"state": "COMPLETE"
}
In this example, the files array has 3 file objects within it. If, for example, a customer would only like to download the application/pdf files, they could isolate those two object IDs and subsequently call the Download a File endpoint to download just those Files.
File Name
The file name convention that Particle follows is Type_FacilityName_Date_UUID.xml e.g., Medical_Summary_Provider_LLC_2022-11-08T000000Z_3ae7fa2a-0bd5-4622-9d19-932a08f4a3b2.xml
By appending the UUID to the file name as the last segment before the extension, Particle is intending to address duplicate file names so that customers are able to distinguish between different files for the same patient.
This file name convention is also reflected in Particle's Sandbox environment!
(Prior to June 2024, the file name convention that Particle followed was Type_FacilityName_Date.xml. If you have not already done so, please make the appropriate plans to ensure that you do not experience any breaking changes, especially if you are expecting or parsing specific fields within the file name.)
Updated 5 months ago